Table of Contents
- Focus on the paper "Learning Transferable Visual Models from Natural Language Supervision"
- Introduction
- Video Presentation and Paper Page of CLIP at ICML
- The model architecture
- Contrastive Learning
- Inference Architecture
- Ablation studies
- Comparison to SOTA ImageNet Model
- Robustness to Natural Distribution Shift
- Zero-Shot vs. Few-Shot
- Comparison to Human
- Internet-as-Pretraining-Dataset Raises Need to Adress Data Overlap with Eval
- Closing Notes by the Authors On Limitations
- CLIP in Context
- Recommended Youtube Videos
- Play With CLIP
- Glossary
Note: This is a living document and is subject to change. The next time you visit, content might differ.
Focus on the paper "Learning Transferable Visual Models from Natural Language Supervision"
Introduction
The paper "Learning Transferable Visual Models from Natural Language Supervision" presents CLIP, a method for Contrastive Language-Image Pretraining. It is a pioneer in leveraging web-scale pairs of images and texts to achieve higher levels of generalization than previous computer vision SOTA models.
At the time of the paper, SOTA models were pretrained on datasets with fixed lists of specific classes. For example ImageNet with 1000 classes.
Models trained in this way will be limited to the specified classes only. This limits their general application, since they can only correctly handle previously specified classes. The task of designing classes and gathering training data is bottlenecked by humans, which means it is not well scalable.
In contrast the internet contains a rich collection of images that have some form of annotation. For example text descriptions for accessibility, text surrounding images, text in photo libraries, Instagram posts etc.
The main idea of the authors, from my understanding, is that leveraging the huge corpus of image-text pairs in the internet would enable a much more general visual understanding. For the paper, the authors created a new dataset which contains image-text pairs for every word that appears at least 100 times in the English Wikipedia.
For me the most important points in this paper are:
- The model architecture that allows a much more general image understanding.
- Contrastive pretraining allows the model to learn robustly from "messy" web data.
- Ablation studies show that CLIP has good zero-shot-transfer.
I will expand in later sections about what I found noteworthy.
Video Presentation and Paper Page of CLIP at ICML
If you want to watch a video for an overview before diving into the paper or want to hear the researchers: There is a video recording of the paper presentation at ICML 2021 by the researchers. It is only 20min short and is an easy watch.
Please visit https://icml.cc/virtual/2021/poster/9193 to watch the video presentation. Below the video is embedded for preview.
The model architecture
s. paper.
Contrastive Learning
s. paper.
Inference Architecture
Efficient Inference
s. paper.
Notably the part about being able to freeze text-encoder classifier. Imagine as a hypernetwork adaptable to tasks.
Prompting change
s. paper.
3.1.4: Notes issues with traditional dataset, amongst which:
- Polysemy: eg “crane” the bird or “crane” the construction machine
- In the CLIP database, normally whole sentences instead of just single words. This skews distribution when applying onto traditional datasets which are a single word only. Applying prompt engineering by creating whole sentences like “A photo of a {label}” the performance increases.
- Adding context in prompts also helps: eg “a satellite image of {}” or “a photo of a {}, a type of pet”.
- The authors propose ensembling as visualized here: https://claude.ai/public/artifacts/4435a9a7-a5e0-47f0-af45-036fa9345325
CLIP can handle issues with polysemy e.g. by giving basic context without added information. E.g. telling it that it has to recognize pets in the Oxford pets dataset.
Ablation studies
Comparison to SOTA ImageNet Model
CLIP has definite advantage in tasks where:
- OCR is required (e.g. SST2, HatefulMemes)
- ImageNet labels do not sufficiently capture diversity of certain objects and thus sacrifice precision by bundling very diverse objects in the same class (e.g. "traffic sign" vs. "stop sign", "warning sign", "speed limit 30" etc).
CLIP is worse in tasks where:
- Images are very small.
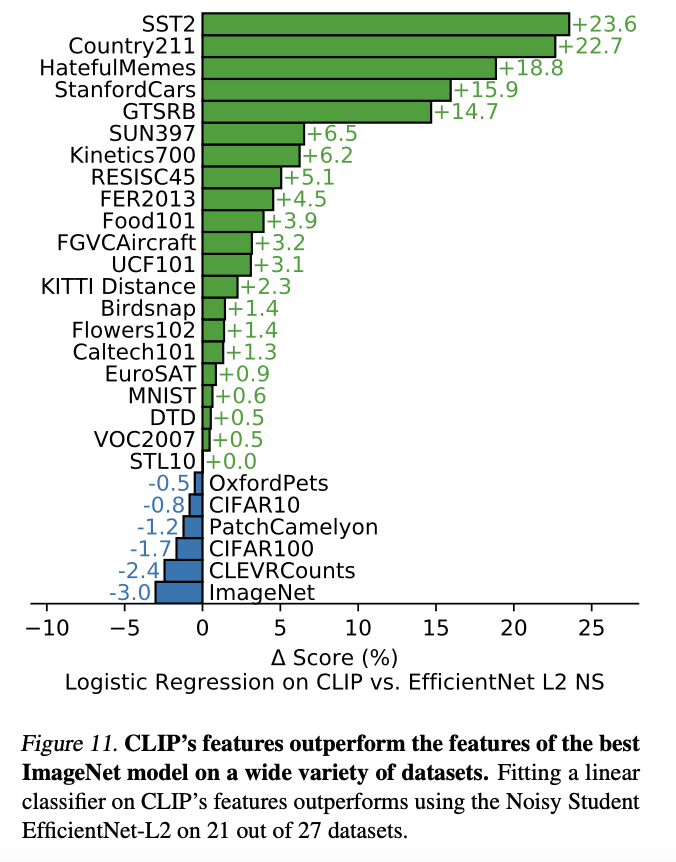
Robustness to Natural Distribution Shift
Adding a logistic regression classifier onto CLIP to fit to ImageNet creates a 9.2% jump in accuracy on ImageNet. But this comes with the cost of reducing performance in other datasets.
On the other hand, adapting CLIP in a zero-shot way by making a classifier only that contains the relevant classes of the dataset improves overall performance over all of the "NDS variations of ImageNet".
Zero-Shot vs. Few-Shot
Zero-shot is actually better than few shot in general until more samples come in. Also the distribution of samples necessary to surpass zero-shot shows which datasets are little covered by the internet-scale database: e.g. remote sensing (satellite imagery).
Comparison to Human
Finding: Humans become much better with 1-shot. This tapers of with more samples. It is also mostly in classes that humans are uncertain about. --> Humans know what they don't know and are also to generalize quite well from a single image only. Probably prior-knowledge is also a factor though.
For some reason the authors did not include 1-shot CLIP performance though.
Internet-as-Pretraining-Dataset Raises Need to Adress Data Overlap with Eval
The authors of the paper also raise the need to address and analyze data overlap.
Because the pretraining of CLIP was done with large-scale internet data, this pretraining data is likely to contain at least some samples very close or identical to samples from eval datasets.
To address this they developed an overlap detector which finds nearest neighbor samples over a threshold and forward those for manual verification.
The authors note two limitations: First, their overlap detector is only tuned with human feedback on the samples which have been identified as relevant nearest neighbors. However they have no insight into the recall of the detector in the rest of the data. Second, the distribution of the dataset can change signinificantly between the resulting subsets "Overlap" and "Clean" of datasets. This needs to be considered when interpreting results. E.g. the performance of CLIP on Kinetics-700 curiously drops by 20% on the "Overlap" subset, which is explained by the "Overlap" subset consisting very many black transition frames.
Note: I myself experienced this when evaluating e.g. agents that have web-search as tool and using established datasets for eval.
Closing Notes by the Authors On Limitations
- CLIP is weak to random in tasks which are not represented in the web-scale dataset.
- CLIP cannot do effective few-shot learning by itself (compare to previous note of the author on how humans improved performance significantly with 1-shot vs. zero-shot).
- CLIP is still brittle in terms of generalization. This can be observed by comparing the quite good performance on digitally rendered text vs. handwritten digits from MNIST.
CLIP in Context
The Vision-Transformer
Dosovitsky
Further Weaknesses of CLIP
- Strong bias on text in images compared to objects in image: Paper
Successors of CLIP and Alternatives to It
First Evolution of CLIP: SigLIP
https://arxiv.org/pdf/2303.15343
Usage of Sigmoid instead of Softmax makes training more robust (esp. on small to medium batch sizes) and resulting models more performant.
A Language-Free Alternative to CLIP: DINO (Language Free SSL)
https://arxiv.org/pdf/2104.14294 https://arxiv.org/pdf/2304.07193
DINO is Meta's alternative approach to CLIP for scaling image understanding. Instead of learning from text-image pairs, it learns image understanding on images only. The outcome is a model that does not directly give out textual descriptions, but has a very strong understanding of images. E.g. it performs well in segmentation tasks and identifying "semantic" parts of an object or doing depth estimation.
Better Through Self-Distillation And SSL: SigLIP 2
https://arxiv.org/pdf/2502.14786
SigLIP 2 puts a big focus on extending SigLIP with grounding, e.g. for better spatial understanding and higher correctness in questions like "How many bottles are to the left of the paper tray?". It uses methods from Self-Supervised-Learning.
Role of CLIP in VLMs
Notable VLMs (open source): Intern VL (IMHO best technical papers to learn about VLMs), Qwen VL, PaliGemma, Moondream
All of these use CLIP-derivatives. Either CLIP itself or SigLIP.
However, https://arxiv.org/pdf/2310.08825 shows that also the usage of a language-free vision encoder like the DINO-family is possible.
All of those follow the same rough architecture which consists of:
# Try to read it. Mermaid integration in the blog is going to come later.
flowchart LR
VE[Vision Encoder] --> MLP[MLP] --> LLM[LLM]
This means that in general both Vision Encoder (e.g. CLIP / SigLIP) are taken as-is from pretraining (same goes for the LLM).
Then the MLP is being trained (as a relatively thin layer) to align the Vision-Encoder and LLM.
Then finally, further training is being done - either fine-tuning or RL.
It can be noted that CLIP-derivatives have an outsize role in open-source models.
However, proprietary models more and more start to use grounding for better spatial understanding. E.g. it is very likely that SigLIP2 is used in Gemini 2.5 which was demonstrated to be capable to drive robotic applications as part of a VLAM (Vision-Language-Action-Model): https://arxiv.org/pdf/2507.10672v1
Applications of CLIP outside of VLMs
CLIP shows flexibility in application. Below you can find some examples incl.
- Image segmentation: Paper [Hugging Face Space](
- Image search: Hugging Face Space 1 Hugging Face Space 2
- Detect AI-generated images: Paper
Recommended Youtube Videos
Lucas Beyer (ex Google Deepmind, now Meta AI), one of the authors of SigLIP, explains CLIP, SigLIP, how SigLIP is integrated into PaliGemma and also some interesting findings.
This video below starts out with an introduction to CLIP and then shows how a language free model like DINO learns to see using Self-Supervised-Learning techniques.
Play With CLIP
Glossary
Hypernetwork
"Hypernetwork" is mentioned in section 3.1.2 of the paper. Specifically:
The cosine similarity of these embeddings is then calculated, scaled by a temperature parameter τ, and normalized into a probability distribution via a softmax. Note that this predic- tion layer is a multinomial logistic regression classifier with L2-normalized inputs, L2-normalized weights, no bias, and temperature scaling. When interpreted this way, the image encoder is the computer vision backbone which computes a feature representation for the image and the text encoder is a hypernetwork (Ha et al., 2016) which generates the weights of a linear classifier based on the text specifying the visual concepts that the classes represent.
From ChatGPT:
A hypernetwork is a neural network that outputs the weights of another network, rather than predictions directly.
- Example: Instead of predicting a label, a hypernetwork might output the parameters of a classifier that can then be applied to some other input.
In CLIP’s case:
- Each class description (“a photo of a dog”, “a photo of a cat”) is passed through the text encoder.
- The output embedding of the text encoder acts as the weight vector for a linear classifier that separates that class from others.
- In other words, the text encoder generates the classifier weights on the fly, conditioned on the text prompt.
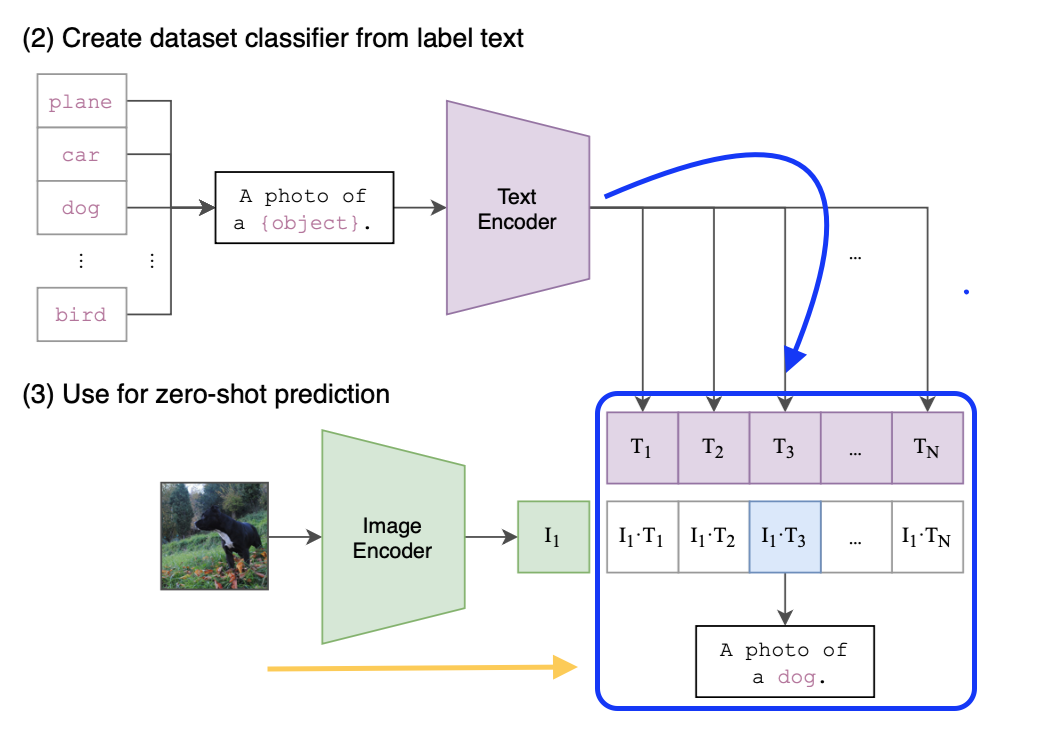
To put this more into context, consider Fig. 1 (2) and (3) with following annotations:
- The blue box is the multinomial logistic regression classifier with L2-normalized inputs, L2-normalized weights, no bias, and temperature scaling. It is formed by combining both the text embeddings and the calculations like cosine similarity, softmax etc. The text embeddings can change and form the weights of this classifier.
- The weights of this classifier change depending on the prediction task at hand. This will change which labels are encoded. This means that the "Text Encoder" puts out the weights of the classifier for prediction. This makes the "Text Encoder" a hypernetwork. It does not create a self-sufficient prediction, but rather weights for another model.
- The "Image Encoder" extracts the features for the multinomial logistic regression classifier, which serve as input (following along the orange arrow).